[Study9] Keras 시작하기
(create: ‘20.6.24, update: ‘20.07.06)
reference : 케라스 Sequential 모델 시작하기, 케라스 함수형 API 첫걸음
케라스 Sequential 모델 시작하기
1. 모델 생성하기
Sequential 모델은 레이어를 선형으로 연결하여 구성합니다. 레이어 인스턴스를 생성자에게 넘겨줌으로써 Sequential 모델을 구성할 수 있습니다.
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
model = Sequential([
Dense(32, input_shape=(784,)),
Activation('relu'),
Dense(10),
Activation('softmax'),
])
또한, add() 메소드를 통해서 쉽게 레이어를 추가할 수 있습니다.
model = Sequential()
model.add(Dense(32, input_dim=784))
model.add(Activation('relu'))
2. 입력형태 지정하기
만들어진 모델은 입력 형태에 대한 정보를 필요로 합니다. 때문에 Sequential 모델의 첫 번째 레이어는 입력 형태에 대한 정보를 받습니다. 두 번째 이후 레이어들은 자동으로 형태를 추정할 수 있기 때문에 형태 정보를 갖고 있을 필요는 없습니다.
형태 정보를 전달하기 위한 방법은 다음과 같습니다.
-
정수형 또는 None으로 구성된 형태 튜플(shape tuple)의 input_shape 인자를 첫번째 레이어에 전달합니다. 여기서 None은 음이 아닌 어떠한 정수를 받을 수 있음을 의미합니다. 참고로 input_shape에는 배치 차원은(batch dimension) 포함되지 않습니다.
model = Sequential() model.add(Dense(32, input_shape=(784,))) -
Dense와 같은 일부 2D 레이어의 경우, 입력 형태를 input_dim 인자를 통해 지정할 수 있으며 일부의 임시적인 3D 레이어는 input_dim과 input_length 인자를 지원합니다.
model = Sequential() model.add(Dense(32, input_dim=784)) -
입력 데이터를 위해 고정된 배치 형태를 필요로 하는 경우에는 레이어에 batch_size 인자를 넘길 수 있습니다. 이는 순환 신경망(recurrent network)를 사용할 때 유용합니다. 예를 들어, batch_size=32와 input_shape=(6,8)을 레이어에 넘겨주면 이후의 모든 입력을 32, 6, 8의 형태로 기대하여 처리합니다.
3. 컴파일
모델을 학습시키기 이전에, compile 메소드를 통해서 학습 방식에 대한 환경설정을 해야 합니다. 다음의 세 개의 인자를 입력으로 받습니다.
-
옵티마이저(optimizer) : rmsprp나 adagrad와 같은 기존의 정규화기에 대한 문자열 식별자 또는 Optimizer 클래스의 인스턴스를 사용할 수 있습니다.
-
손실함수(loss function) : 모델이 최적화에 사용되는 목적 함수입니다. categorical_crossentropy 또는 mse와 같은 기존의 손실 함수의 문자열 식별자 또는 목적 함수를 사용할 수 있습니다. 해결할 문제에 따른 손실함수 사용 사례들:
# For a multi-class classification # sparse_categorical_crossentropy ; 다중 분류 손실함수(integer type 클래스) # categorical_crossentropy ; 다중 분류 손실함수(one-hot encoding 클래스) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) # For a binary classification model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy']) # For a mean squared error regression model.compile(optimizer='rmsprop', loss='mse') -
기준(metric) 리스트 : 분류 문제에 대해서는 metrics=[‘accuracy’] 처럼 설정합니다. metric은 문자열 식별자 또는 사용자 정의 metric 함수를 사용할 수 있습니다.
4. 학습
케라스 모델들은 입력 데이터와 라벨로 구성된 Numpy 배열 위에서 이루어집니다. 모델을 학습기키기 위해서는 일반적으로 fit 함수를 사용합니다. 여기서 자세한 정보를 알 수 있습니다.
-
binary classification
# For a single-input model with 2 classes (binary classification): model = Sequential() model.add(Dense(32, activation='relu', input_dim=100)) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy']) # Generate dummy data import numpy as np data = np.random.random((1000, 100)) labels = np.random.randint(2, size=(1000, 1)) # Train the model, iterating on the data in batches of 32 samples model.fit(data, labels, epochs=10, batch_size=32) -
categorical classification
# For a single-input model with 10 classes (categorical classification): model = Sequential() model.add(Dense(32, activation='relu', input_dim=100)) model.add(Dense(10, activation='softmax')) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) # Generate dummy data import numpy as np data = np.random.random((1000, 100)) labels = np.random.randint(10, size=(1000, 1)) # Convert labels to categorical one-hot encoding one_hot_labels = tf.keras.utils.to_categorical(labels, num_classes=10) # Train the model, iterating on the data in batches of 32 samples model.fit(data, one_hot_labels, epochs=10, batch_size=32)
케라스 함수형 API 첫걸음
케라스 함수형 API는 다중-아웃풋 모델, 비순환 유향 그래프, 혹은 레이어 공유 모델과 같이 복잡한 모델을 정의하는데 최적의 방법입니다.
이 가이드는 독자가 Sequential 모델에 대한 지식이 있다고 가정합니다.
1. 밀집 연결 네트워크(예시)
밀집 연결 네트워크를 구현하기에는 Sequential 모델이 더 적합한 선택이겠지만, 아주 간단한 예시를 위해서 케라스 함수형 API로 구현해 보겠습니다.
-
레이어 인스턴스는 (텐서에 대해) 호출 가능하고, 텐서를 반환합니다.
-
인풋 텐서와 아웃풋 텐서는 Model을 정의하는데 사용됩니다.
-
이러한 모델은 케라스 Sequential 모델과 완전히 동일한 방식으로 학습됩니다.
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
# 이는 텐서를 반환합니다
inputs = Input(shape=(784,))
# 레이어 인스턴스는 텐서에 대해 호출 가능하고, 텐서를 반환합니다
x = Dense(64, activation='relu')(inputs)
predictions = Dense(10, activation='softmax')(x)
# 이는 Input 레이어와 3개의 Dense 레이어를 포함하는 모델을 만들어 냅니다
model = Model(inputs=inputs, outputs=predictions)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(data, labels) # starts training
함수형 API를 사용하면 학습된 모델을 재사용하기 편리합니다: 어느 모델이건 텐서에 대해 호출하여 레이어처럼 사용할 수 있습니다. 모델을 호출하면 모델의 구조만 재사용하는 것이 아니라 가중치까지 재사용되는 것임을 참고하십시오.
from tensorflow.keras.layers import TimeDistributed
# 20 시간 단계의 시퀀스에 대한 입력 텐서로, 각각 784 차원의 벡터를 담고 있습니다.
input_sequences = Input(shape=(20, 784))
# 인풋 시퀀스의 모든 시간 단계에 이전 모델을 적용합니다.
# 이전 모델의 아웃풋이 10 방향 소프트맥스였으므로, 아래 레이어의 출력은 크기 10의 벡터 20개로 이루어진 시퀀스입니다.
processed_sequences = TimeDistributed(model)(input_sequences)
2. 다중-인풋과 다중-아웃풋 모델(예시)
다중 인풋과 아웃풋을 다루는 모델은 함수형 API를 사용하기 특히 적합한 사례입니다. 함수형 API를 사용해서 복잡하게 얽힌 많은 수의 데이터 줄기를 간편하게 관리할 수 있습니다.
다음의 모델을 고려해 봅시다. 얼마나 많은 트위터에서 특정 뉴스 헤드라인이 얼마나 낳은 리트윗과 좋아요를 받을지 예측하려고 합니다. 모델에 대한 주요 인풋은 단어 시퀀스로 표현된 헤드라인 자체이지만, 문제를 조금 더 흥미롭게 풀기 위해, 보조 인풋으로 헤드라인이 올려진 시간 등과 같은 추가 데이터를 받도록 합시다. 두 개의 손실 함수를 통해 모델을 감독합니다. 주요 손실 함수를 모델의 초기 단계에 사용하는 것이 심화 모델에 있어 적절한 정규화 메커니즘입니다.
이 모델은 다음과 같이 구성됩니다:
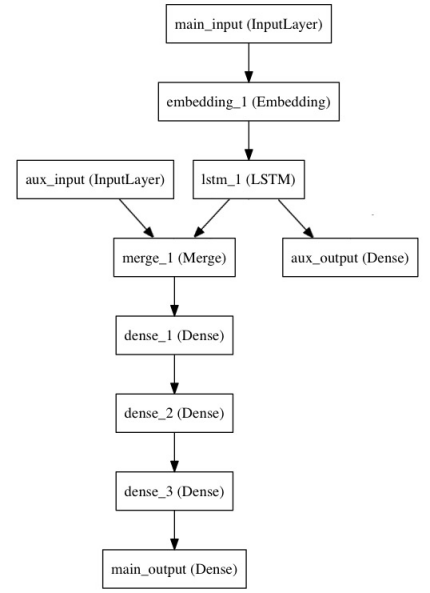
함수형 API로 모델을 구현해 봅시다.
주요 인풋은 헤드라인을 (각 정수가 단어 하나를 인코딩하는) 정수 시퀀스의 형태로 전달받습니다. 정수는 1에서 10,000사이의 값이며 (10,000 단어의 어휘목록), 시퀀스의 길이는 100 단어입니다.
from tensorflow.keras.layers import Input, Embedding, LSTM, Dense
from tensorflow.keras.models import Model
# 헤드라인 인풋: 1에서 10000사이의 100개 정수로 이루어진 시퀀스를 전달받습니다
# "name"인수를 전달하여 레이어를 명명할 수 있음을 참고하십시오.
main_input = Input(shape=(100,), dtype='int32', name='main_input')
# 이 임베딩 레이어는 인풋 시퀀스를 밀집 512 차원 벡터의 시퀀스로 인코딩합니다
x = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input)
# 장단기 메모리(LSTM)는 벡터 시퀀스를 전체 시퀀스에 대한 정보를 포함하는 단일 벡터로 변형합니다
lstm_out = LSTM(32)(x)
다음에서는 보조 손실을 추가하여, 메인 손실이 높아지더라도 장단기 메모리와 임베딩 레이어가 매끄럽게 학습될 수 있도록 합니다.
auxiliary_output = Dense(1, activation='sigmoid', name='aux_output')(lstm_out)
이 시점에서 보조 인풋을 장단기 메모리(LSTM) 아웃풋에 연결하여 모델에 전달합니다:
auxiliary_input = Input(shape=(5,), name='aux_input')
x = tf.keras.layers.concatenate([lstm_out, auxiliary_input])
# 심화 밀집 연결 네트워크를 상층에 쌓습니다
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
# 끝으로 주요 로지스틱 회귀 레이어를 추가합니다
main_output = Dense(1, activation='sigmoid', name='main_output')(x)
두 개의 인풋과 두 개의 아웃풋을 갖는 모델을 정의합니다:
model = Model(inputs=[main_input, auxiliary_input], outputs=[main_output, auxiliary_output])
이제 모델을 컴파일하고, 0.2의 가중치를 보조 손실에 배당합니다. 리스트나 딕셔너리를 사용해서 각기 다른 아웃풋에 별도의 loss_weights 혹은 loss를 특정할 수 있습니다. 다음에서는 loss인수로 단일 손실을 전달하여 모든 아웃풋에 대해 동일한 손실이 사용되도록 합니다.
model.compile(optimizer='rmsprop', loss='binary_crossentropy',
loss_weights=[1., 0.2])
인풋 배열과 표적 배열의 리스트를 전달하여 모델을 학습시킬 수 있습니다:
model.fit([headline_data, additional_data], [labels, labels],
epochs=50, batch_size=32)
인풋과 아웃풋이 명명되었기 때문에(이름은 “name” 인수를 통해 전달합니다), 다음과 같이 모델을 컴파일 및 학습시킬 수도 있습니다:
model.compile(optimizer='rmsprop',
loss={'main_output': 'binary_crossentropy', 'aux_output': 'binary_crossentropy'},
loss_weights={'main_output': 1., 'aux_output': 0.2})
model.fit({'main_input': headline_data, 'aux_input': additional_data},
{'main_output': labels, 'aux_output': labels},
epochs=50, batch_size=32)