[Study5] NLP(Natural Language Processing) 개요
[AI와 QA의 만남] - Study Day5 (학습일: ‘20.05.26, update: ‘20.07.06)
NLP(Natural Language Processing)
자연어 처리는 텍스트에서 의미있는 정보를 분석, 추출하고 이해하는 일련의 기술집합 이다.
우리 일상에도 다양한 NLP 응용사례가 있다;
- 검색엔진과 같은 정보검색 시스템
- 스팸 필터
- 감성분석
- 맞춤법 검사
- 텍스트 요약
- 대화 시스템
- 기계 번역 등
자연어처리 용어 정의
- 담화 : 문장이 연속되어 이루어지는 말의 단위, 문단
- 문장 : 완결된 내용을 나타내는 최소 단위
- 어절 : 문장을 구성하는 단위(주어, 서술어, 관형어, 등). 띄어쓰기 단위
- 단어 : 어절을 구성하는 요소. 형태소의 조합으로 구성되어 있음(관형사, 명사, 조사, 동사). 품사를 붙일 수 있는 단위
- 형태소(Morpheme) : (형태론적으로, 문법적으로) 의미를 가진 문법의 최소 단위(어근 분리)

- 코퍼스(Corpus, 말뭉치) : 자연언어 연구를 위해 특정한 목적을 가지고 언어의 표본을 추출한 집합이다. 언어의 빈도와 분포를 확인할 수 있는 자료이며, 현대 언어학 연구에 필수적인 자료이다. ‘컴퓨터로 분석하기에 용이하도록 “잘” 모아둔 다량의 텍스트 데이터’ 이다
- Tokenizing(토큰화) : 주어진 코퍼스(corpus)에서 토큰(token)이라 불리는 단위로 나누는 작업을 토큰화(tokenization)라고 부른다. 토큰의 단위가 상황에 따라 다르지만, 보통 의미있는 단위로 토큰을 정의 한다. 단어 토큰화(Word Tokenization), 문장 토큰화(Sentence Tokenization) 등
- POS(Part-of-Speech, 품사) Tagging : 품사 태깅은 형태소의 뜻과 문맥을 고려하여 형태소에 마크업을 추가하는 일. 단어 토큰화 과정에서 각 단어가 어떤 품사로 쓰였는지를 구분해놓는 일
자연어 분석 기술 분류
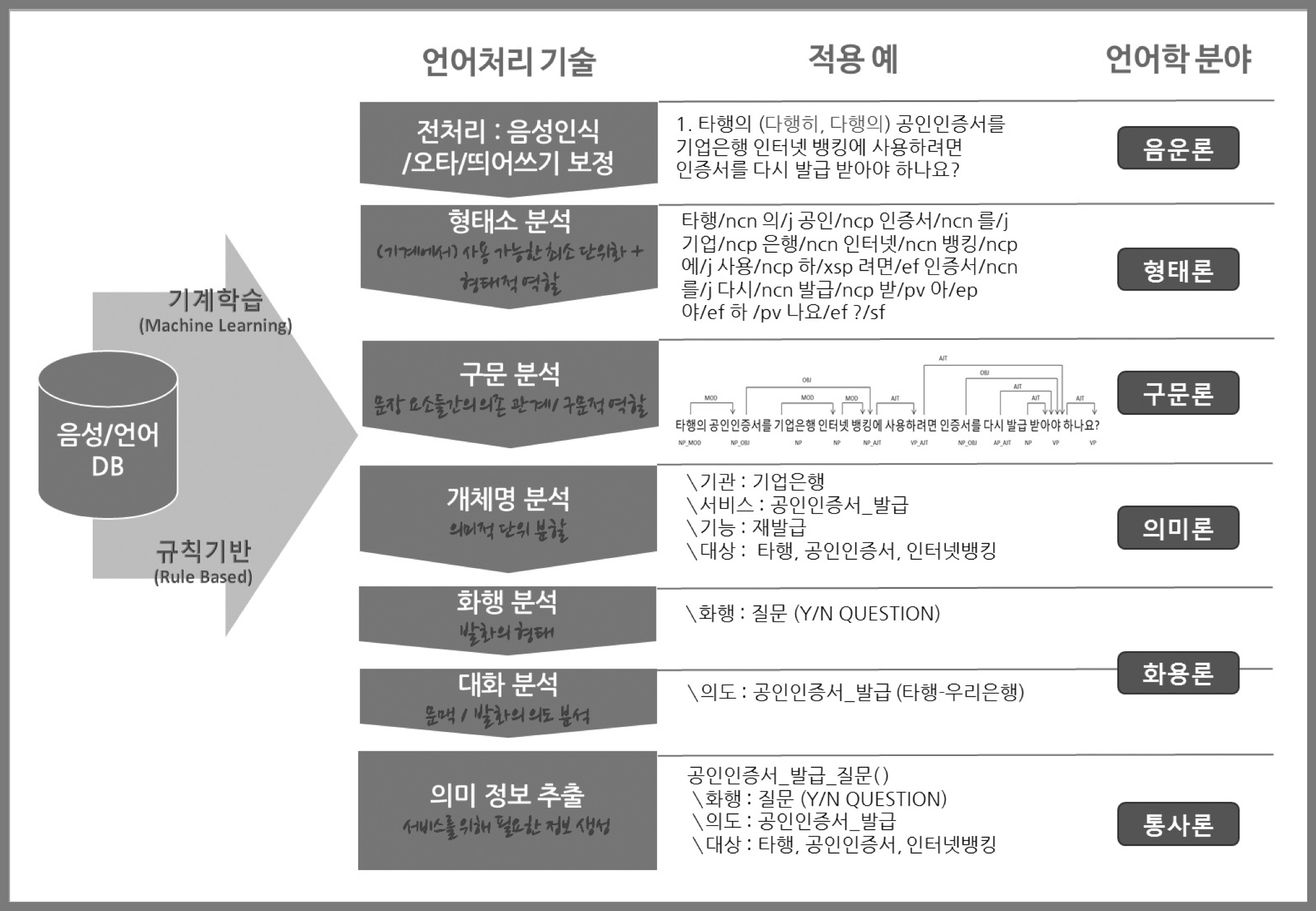
참조: https://www.korean.go.kr/nkview/nklife/2017_4/27_0401.pdf
- 형태소 분석 : 입력된 문장을 형태소 단위로 분류하고 품사를 부착
- 형태소를 비롯하여, 어근, 접두사/접미사, 품사(POS, part-of-speech) 등 다양한 언어적 속성의 구조를 파악하는 것
- 토큰 분리, 어간 추출, 품사 부착, 색인, 벡터화
- 구문 분석 : 주어, 목적어, 서술어와 같은 구문단위를 찾음
- 문장 경계 인식, 구문분석, 공기어, 개체명 사전 구축(PLOT, 수치, 외국어 한글 표기), 개체명 인식
- 의미 분석 : 문장이 의미적으로 올바른 문장인지를 판단
- 대용어 해소(대명사, 두문자어, 약어, 수치), 의미 중의성 해결(동명이인 ,이명이인)
- 담화 분석(담론 분석) : 대화 흐름상 어떤 의미를 가지는지를 찾음
- 문맥 구조 분석(문장들의 연관관계), 의도분석(중의성 해소)
- 분류, 군집, 중복, 요약, 가중치, 순위화, 토픽 모델링, 이슈 트래킹, 평판분석, 감성분석, 복합논증분석
형태소 분석, 구문 분석 분야는 어느 정도 기술이 성숙되어 있으나, 의미 분석, 담화 분석 등은 아직도 연구가 진행중인 분야이다.
언어의 벡터 표현
- 다양한 단어 표현 방법
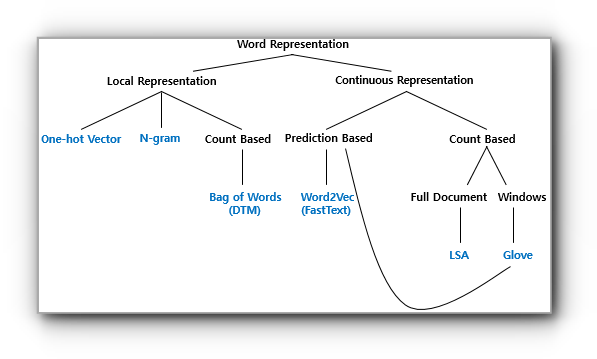
Bag of Words(BoW)
Bag of Words란 단어들의 순서는 전혀 고려하지 않고, 단어들의 출현 빈도(frequency)에만 집중하는 텍스트 데이터의 수치화 표현 방법이다. Bag of Words를 직역하면 단어들의 가방이라는 의미이다. 단어들이 들어있는 가방을 상상해보면, 갖고있는 어떤 텍스트 문서에 있는 단어들을 가방에다가 전부 넣고 이 가방을 흔들어 단어들을 섞은 후 해당 문서 내에서 특정 단어가 N번 등장했다면, 이 가방에는 그 특정 단어가 N개 있게된다. 또한 가방을 흔들어서 단어를 섞었기 때문에 더 이상 단어의 순서는 중요하지 않게 된다.
-
문서 단어 행렬(Document-Term Matrix, DTM)
문서 단어 행렬(Document-Term Matrix, DTM)이란 다수의 문서에서 등장하는 각 단어들의 빈도를 행렬로 표현한 것을 말한다. 쉽게 생각하면 각 문서에 대한 BoW를 하나의 행렬로 만든 것으로 생각할 수 있으며, BoW와 다른 표현 방법이 아니라 BoW 표현을 다수의 문서에 대해서 행렬로 표현하고 부르는 용어이다.
-
TF-IDF(Term Frequency-Inverse Document Frequency)
TF-IDF(Term Frequency-Inverse Document Frequency)는 단어의 빈도와 역 문서 빈도(문서의 빈도에 특정 식을 취함)를 사용하여 DTM 내의 각 단어들마다 중요한 정도를 가중치로 주는 방법이다. 사용 방법은 우선 DTM을 만든 후, TF-IDF 가중치를 부여한다. 특정 문서 내에서 단어 빈도가 높을 수록, 그리고 전체 문서들 중 그 단어를 포함한 문서가 적을 수록 TF-IDF값이 높아진다.
TF-IDF는 주로 문서의 유사도를 구하는 작업, 검색 시스템에서 검색 결과의 중요도를 정하는 작업, 문서 내에서 특정 단어의 중요도를 구하는 작업 등에 쓰일 수 있다.
Word2Vec
Word2Vec은 단어에서 문맥을 예측하거나, 문맥에서 단어를 예측하는 방법이다. 대표적인 워드 임베딩(Word Embedding) 방법이며, CBOW 방식과 Skip-Gram 방식의 단어 임베딩을 구현한 C++ 라이브러리로 구글에 있던 Mikolov 등이 개발하였다.
-
Word Embedding : 워드 임베딩(Word Embedding)은 단어를 벡터로 표현하는 방법으로, 주로 희소 표현에서 밀집 표현으로 변환하는 것을 의미한다.
-
단어의 국소표현으로는 단어의 의미를 알 수 없다.

-
분포 가설 : 비슷한 문맥을 가진 단어는 비슷한 의미를 갖는다. (현대의 통계적/확률적 자연어 처리에서 사용하는 기본 가설)
-
문맥창(Window)

-
단어문맥행렬
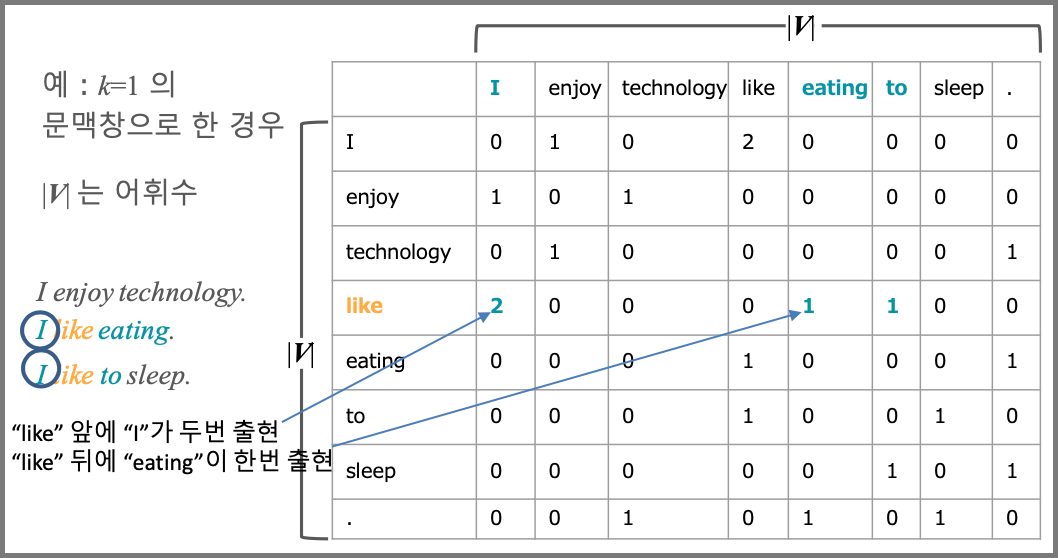
-
CBOW(Continuous Bag of Words) : 문맥으로부터 단어를 예측하는 방법
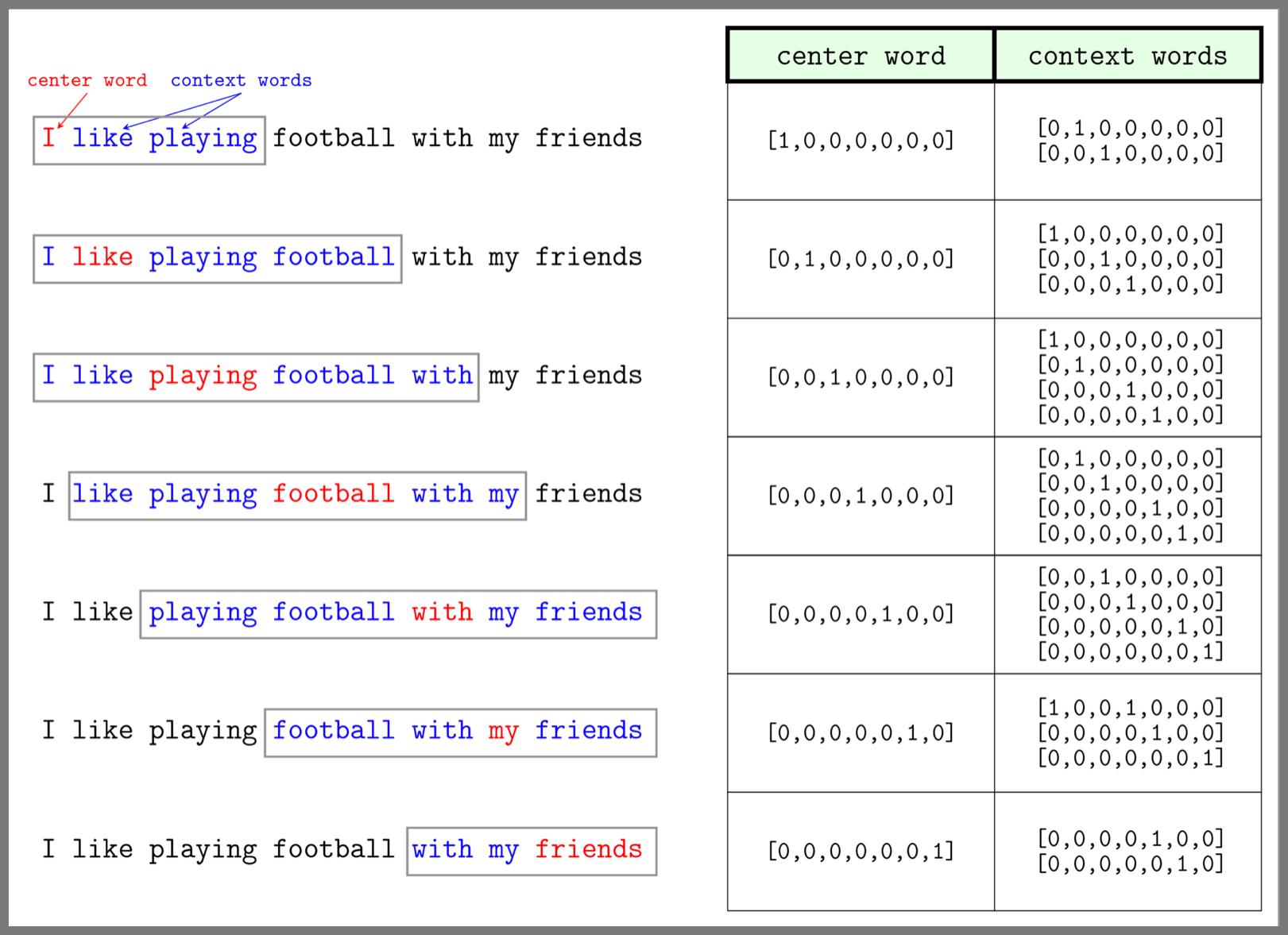
참조 : 머신러닝의 자연어 처리기술(1) Slideshare 자료
-
Skip-Gram : 단어로 부터 문맥을 예측하는 방법
-
Word2vec 참고자료 : The Illustrated Word2vec
한국어 형태소 분석기와 말뭉치들
KoNLPy 홈페이지의 참고문헌 페이지에 다양한 언어로 구현된 형태소 분석기, 말뭉치 및 NLP 도구들의 링크가 정리되어 있다.
KoNLPy(코엔엘파이)
KoNLPy는 한국어 자연어처리를 위한 파이썬 패키지 이다. 대표적인 자연어처리 패키지로는 NLTK가 있으며, NLTK로도 한국어 자연어처리를 할 수는 있지만 한국어를 제대로 처리하기 위해서는 한국어를 지원하는 패키지가 필요 하다.
- KoNLPy 설치방법
-
OS와 비트 수가 일치하고, 버전이 1.7 이상인 자바(JDK)가 설치되어 있어야 한다. JAVA_HOME을 설정 한다. 자바(JAVA) 다운로드 및 설치하기. 환경설정 세팅하는 법 블로그 글을 참고한다.
-
Windows 환경에서는 Python Java 라이브러리(JPype)를 별도로 설치 해야 한다. 설치된 Python 버전에 맞는 JPype를 다운로드 후, 다운로드 한 JPype 파일이 있는 폴더에서 아래 명령으로 설치한다. wheel 파일명에서 “-cp37-“ 부분이 python 3.7 버전을 의미한다.
pip install JPype1‑0.7.5‑cp37‑cp37m‑win_amd64.whl -
KoNLPy 패키지를 설치 한다.
pip install konlpy -
pip install konlpy 실행 시 SSL 인증서 에러가 나는 경우 아래 명령을 사용하여 설치 합니다.
pip --trusted-host pypi.org --trusted-host files.pythonhosted.org install konlpy -
NLTK 패키지도 설치 한다.
pip install nltk
-
아나콘다 환경에서는 pip install 명령어 대신 conda install 명령어를 사용하여 설치한다.
KoNLPy 실습
-
KoNLPy 형태소 분석, POS Tagging 실습 : aiqa_study repository를 clone 후 jupyter notebook에서 “NLP-형태소분석_POS_Taggers.ipynb” 파일 학습
-
KoNLPy 워드 클라우드 : aiqa_study repository를 clone 후 jupyter notebook에서 “NLP_wordcloud.ipynb” 파일 학습

-
코드에 matplotlib, wordcloud 한글 폰트 설정은 Windows와 MAC의 환경에 따라 설정을 변경해서 사용해야 함
- MAC에서는 ‘for MAC’이라는 코멘트가 있는 행을 활성화 (해당 라인의 맨 앞에 있는 코멘트 기호 ‘#’을 제거하고, ‘for Windows’ 행을 주석 처리)
- Windows에서는 ‘for Windwos’라는 코멘트가 있는 행을 활성화 (해당 라인의 맨 앞에 있는 코멘트 기호 ‘#’을 제거하고, ‘for MAC’ 행을 주석 처리)
자연어처리 학습 참고자료
- 딥 러닝을 이용한 자연어 처리 입문 : https://wikidocs.net/book/2155
- NLP 학습용 Github Repository : https://github.com/sungalex/nlp