[Study7] STT(Speech to Text) - Google ML API 사용하기
[AI와 QA의 만남] - Study Day7 (학습일: ‘20.06.16, create: ‘20.06.15, update: ‘20.07.06)
딥러닝 음성인식 - STT(Speech to Text)
음성인식이란
-
소리는 시간에 따른 기압의 분포이다(여러 개 주파수의 합이 신호의 세기로 나타난다). 즉, 일정한 시간을 주기로 측정한 기압의 차이이다.
-
음성인식이란 음성신호로부터 Text Data를 추출 하는 것이다.

- 입력된 음성이 어떤 단어들로 이루어져 있을 확률이 가장 높은가를 찾는 문제이다.
-
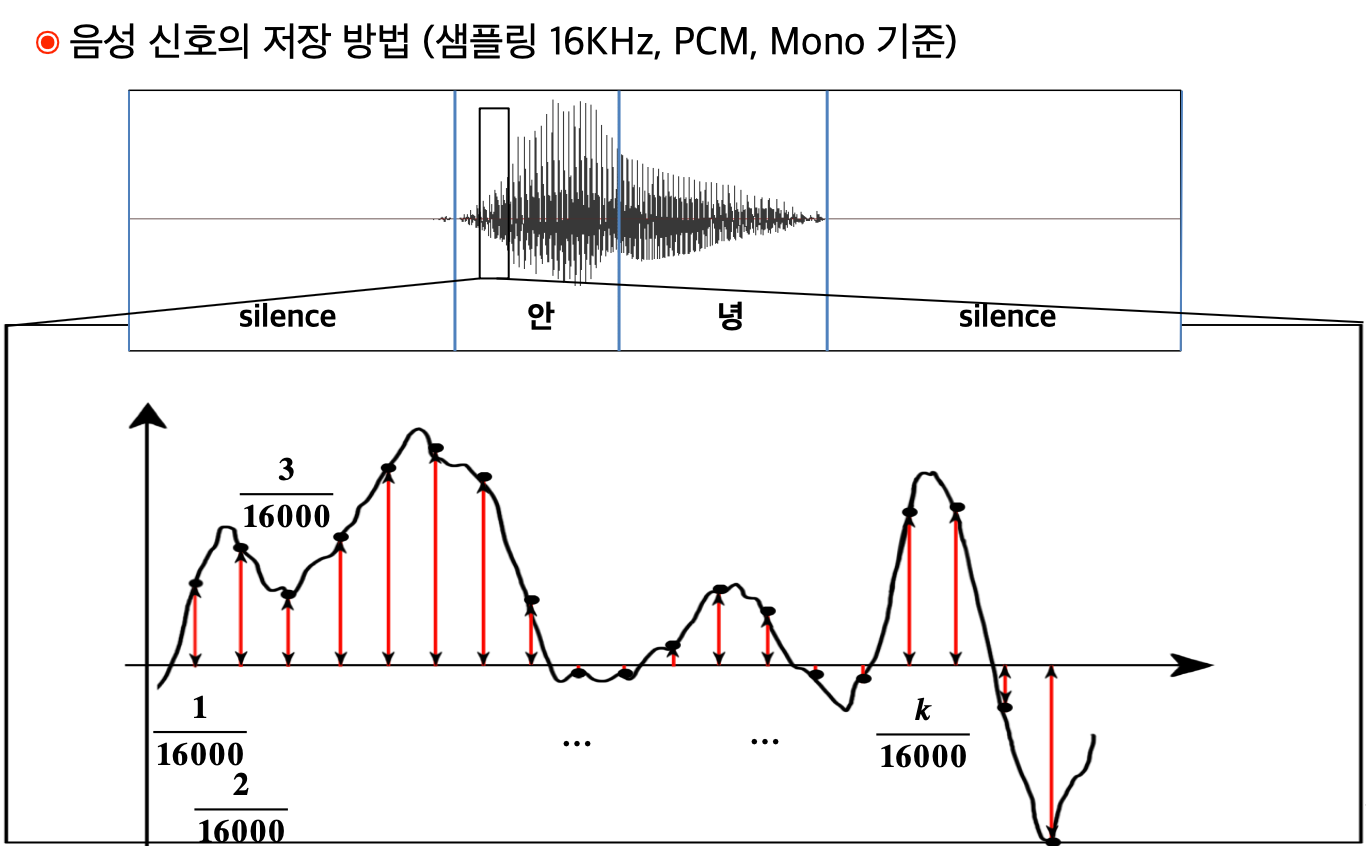
음성신호의 저장 방법 : 대표적인 방법이 PCM 이다.
-
PCM(Pulse Code Modulation) : 아날로그 음성 신호를 표본화 -> 양자화 -> 부호화 과정을 통해 디지털 음성 신호로 변환함 (PCM 설명은 여기 참조)
-
Sampling Rate가 44.1kHz라면, 음성 신호를 1초에 44,100번 샘플링해서, 각각의 샘플링된 신호를 2Bytes(65,536개의 크기)로 저장 ==> 엄청난 데이터량
-
-
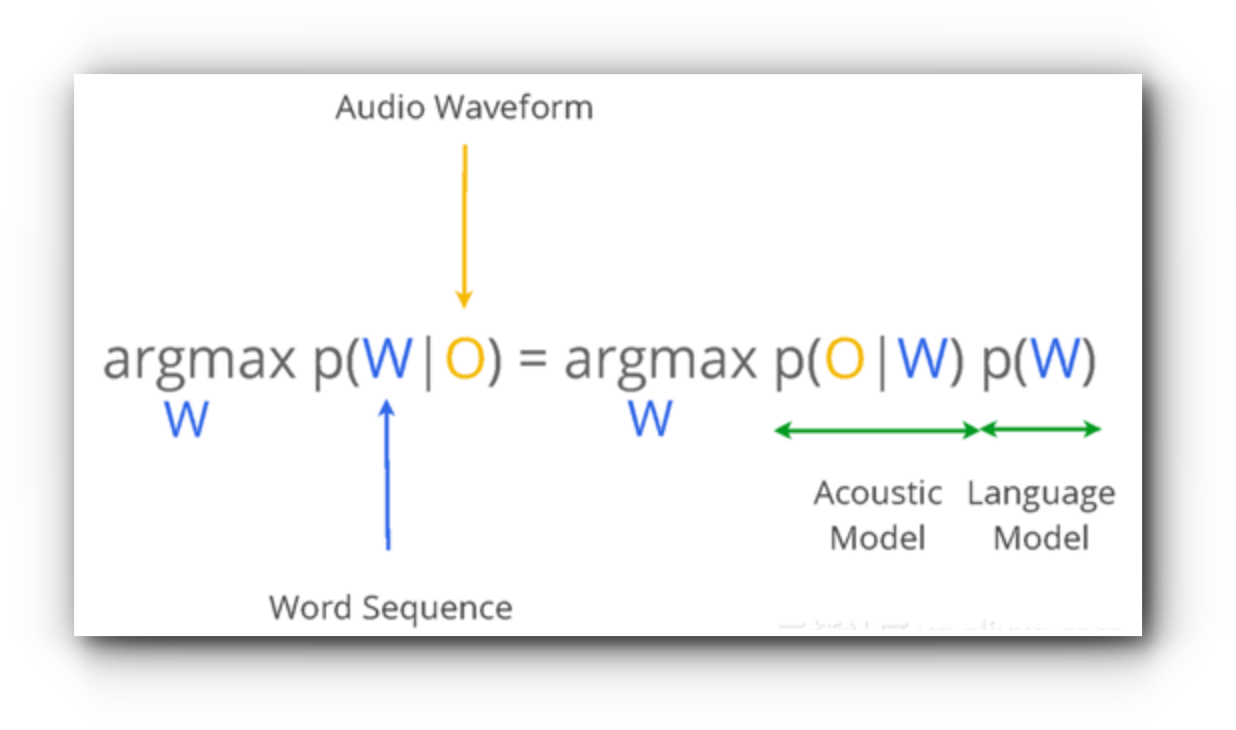
음성인식의 수식 표현 : 일정 길이 T 동안 입력된 음성 Sequence X(또는 O)에 대해서 인식기가 표현할 수 있는 모든 단어들의 조합 중 가장 가능성이 높은 단어열 W는 무언인가?

-
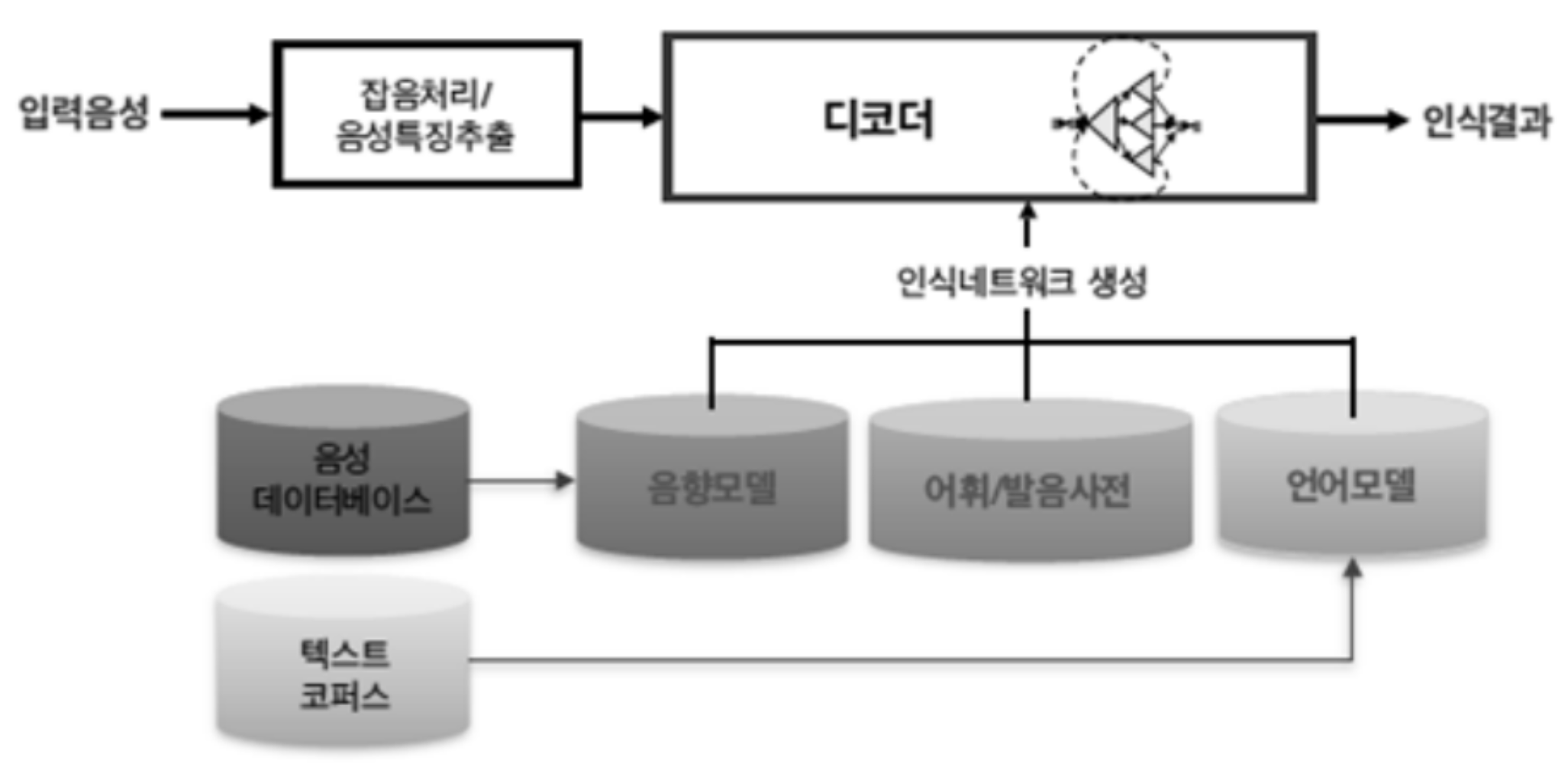
ASR(automatic speech recognition) System 구성
-
음향모델, 발음사전, 언어모델이 학습단계 결과물 이다.
-
음향모델(Acoustic Model) : 음성을 0.02초 구간을 0.01초씩 시간축에 따라 움직이며 만든 특징 벡터열 X와 어휘 셋 W에 대해 P(X | W) 확률을 학습하는 과정(해당 언어의 음운 환경별 발음의 음향적 특성을 확률 모델로 대표 패턴을 생성하는 과정) 이다. 음향모델 학습을 위해서는 음성데이터와 이 음성데이터가 무슨 문장을 발성한 것인지에 대한 원고가 있어야 한다. 음성을 듣고 사람이 정답을 달아주는(원고를 작성) 옮겨쓰기(Transcription) 작업이 필요하다.
- 발성기관인 성대의 떨림 정도나 모양이 급격하게 변할 수 없으므로, 음성은 짧은 구간(보통 0.02초) 동안의 주기적인 단위로 음성을 분석하여 소리가 만들어진 상태를 예측한다.
-
언어모델(Language Model) : 방대한 텍스트를 분석해 모델을 만들어 현재 인식되고 있는 단어들 간의 결합 확률을 예측하는 과정이다. 언어모델에서는 특정 단어 다음에 나올 단어의 확률 추정이 이뤄진다. 발음이 비슷한 단어가 많거나 불분명하게 발음되어 음향모델만으로 판단했을 때 잘못된 인식이 발생할 확률을 낮추는 역할을 한다.
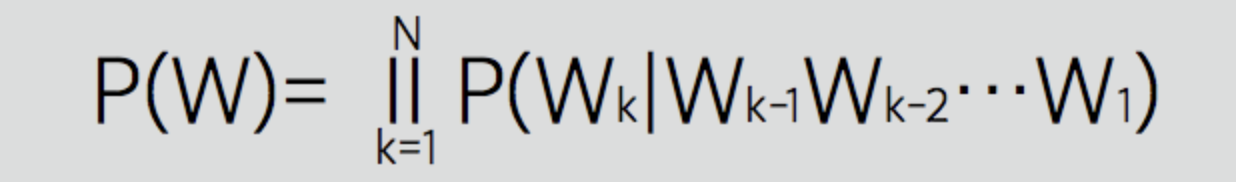
-
어휘/발음사전(Pronunciation Lexicon) : 텍스트를 소리 나는 대로 변환하는 음소변환을 통해 발음사전(단어의 발음 표현)을 구축하고, 방언/발화습관/어투 등 다양한 패턴을 반영하여 사전을 구축한다.
[참조] : 음성 언어 처리 기술, 어디까지 왔나?
-
-
음성인식을 어떻게 처리하는가?
-
통계적 모델링 방법

-
고전적인 음성인식은 음소를 GMM(Gaussian Mixture Model)로 모델링 하고, 이 음소들의 연속적인 변화를 HMM(Hidden Markov Model)으로 예측하는 방법을 사용한다.
-
HMM은 시스템이 은닉된 상태와 관찰 가능한 결과의 두 가지 요소로 이루어졌다고 보는 모델이다. x(t)는 시간 t에서의 은닉 상태(hidden state)의 확률 이며, y(t)는 시간 t에서의 관측값(observation)의 확률이다. 한 상태(state)의 확률은 단지 그 이전 상태(또는 그 이전 r개의 상태)에만 의존한다는 것이 마코프 체인의 가정이다. 즉, 한 상태에서 다른 상태로의 전이(transition)는 그동안 상태 전이에 대한 긴 이력(history)을 필요로 하지 않고 바로 직전 상태에서의 전이로 추정할 수 있다는 것이다.
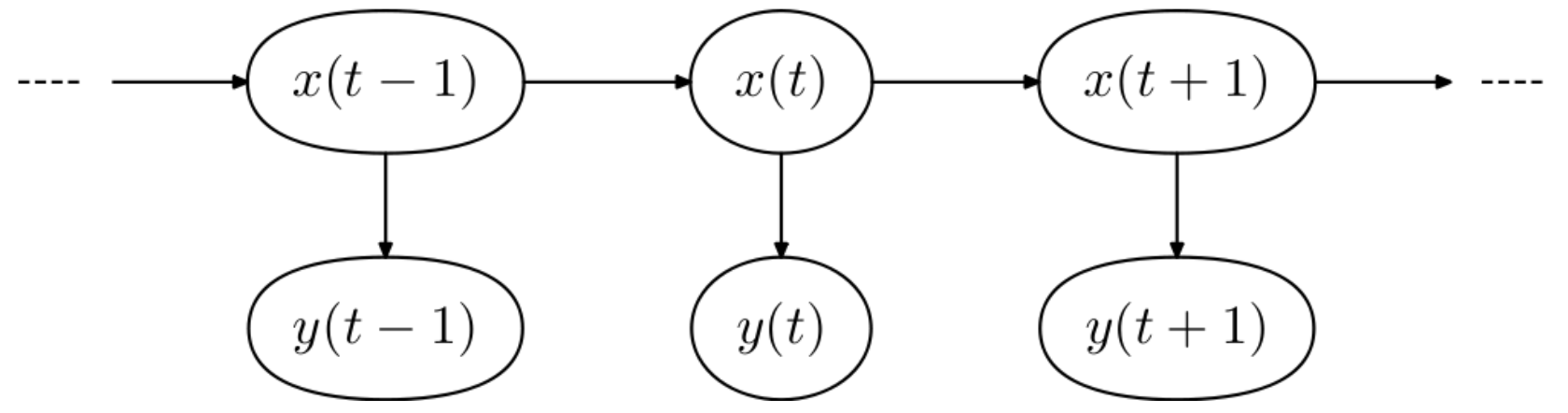
-
마코프 체인은 아래와 같이 조건부 확률 수식으로 표현할 수 있다.
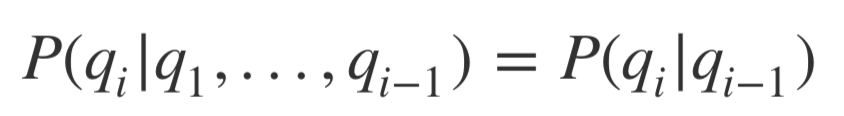
-
GMM은 음성의 음향 특성의 분포를 모델링하는데 사용되고, HMM은 음성 신호의 시간 시퀀스를 모델링하는데 사용된다.
-
GMM은 Gaussian 분포가 여러 개 혼합된 clustering 알고리즘 이다. 현실에 존재하는 복잡한 형태의 확률 분포를 K개의 Gaussian distribution을 혼합하여 표현하자는 것이 GMM의 기본 아이디어 이다.
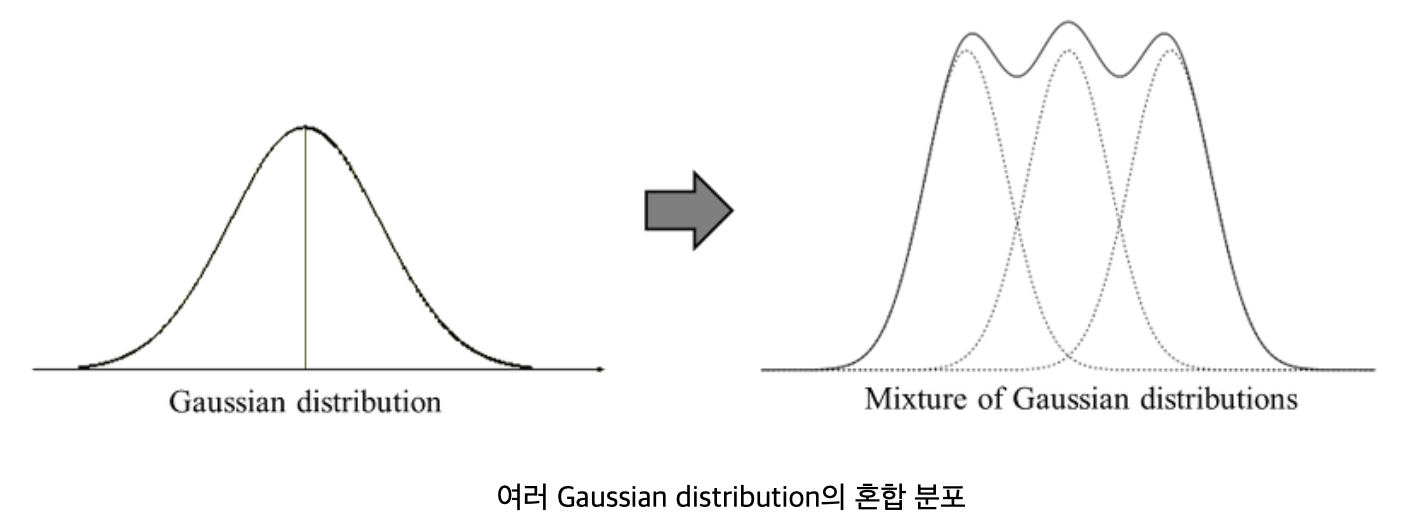
-
-
DNN(Deep Neural Network) 모델
-
GMM 확률 모델 부분을 DNN(Deep Learning)으로 대체하고, HMM으로 음성의 변화를 예측하는 방법을 사용한다. (최근에는 HMM 부분까지 Deep Learning 모델로 대체하는 모델에 대한 연구가 많이 진행되고 있다.)
-
음성 특징 추출
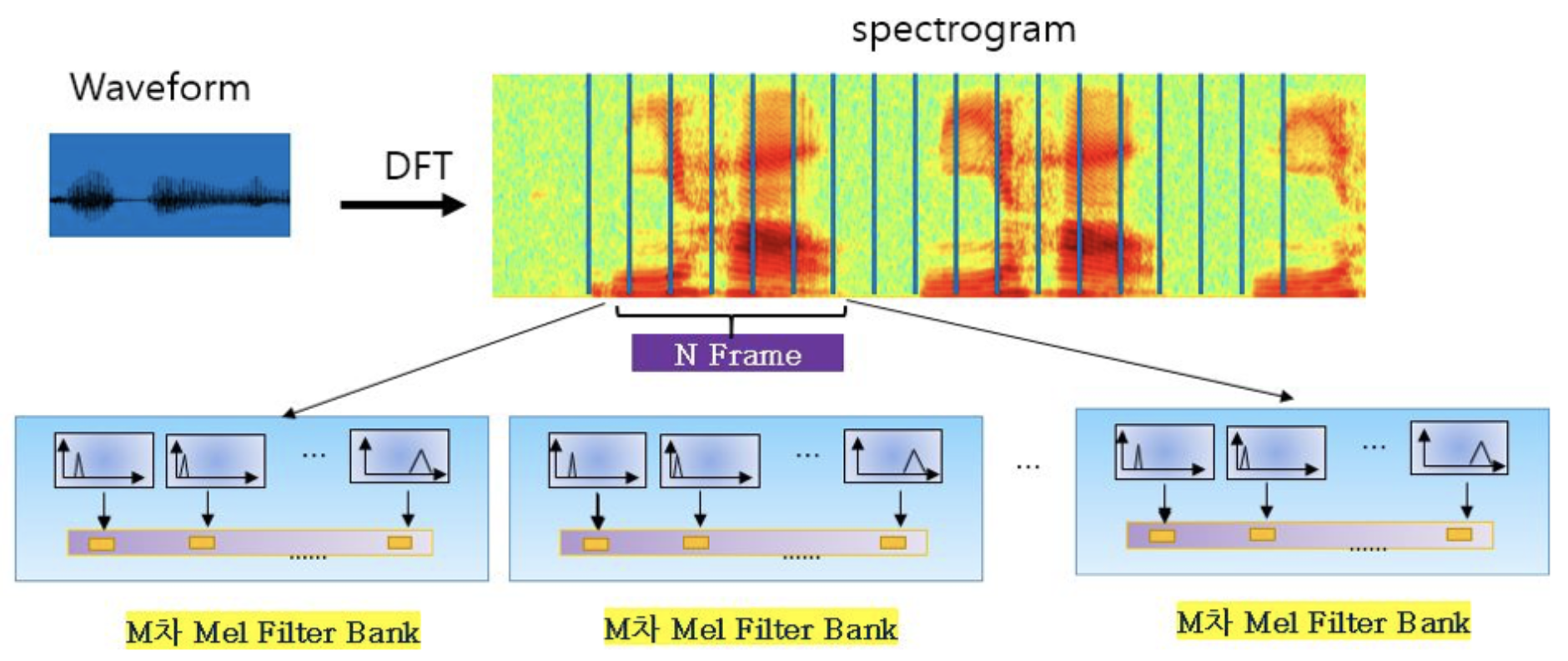
-
음향모델
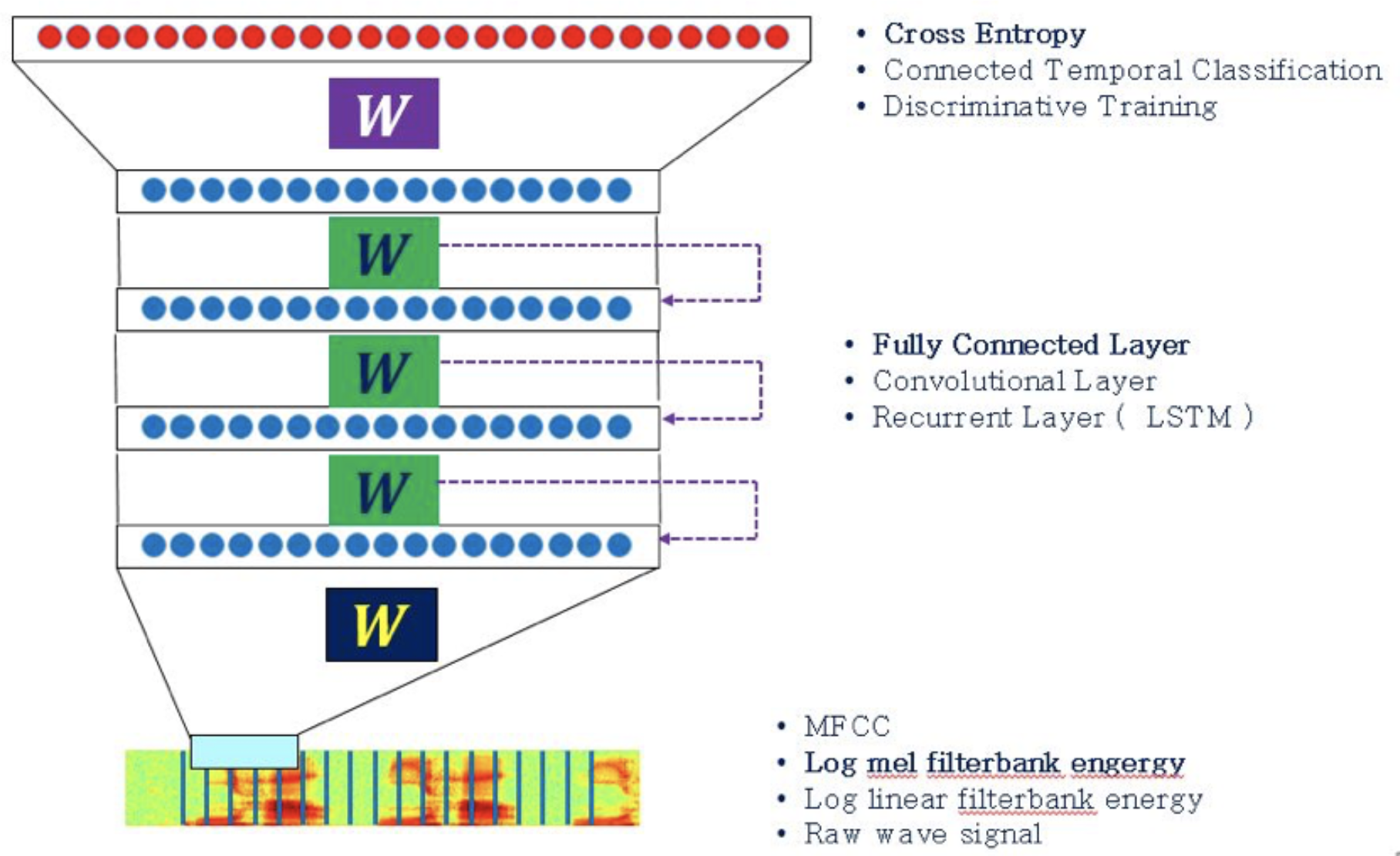
-
ASR DNN 모델에 대한 설명 자료 : 카카오 AI 리포트 - 음성인식 방법과 카카오i의 음성형엔진
-
딥러닝(Deep Learning)을 이용한 음성 인식(Speech Recognition) 소개 자료 : 기계 학습(Machine Learning, 머신 러닝)은 즐겁다! Part 6
-
-
음성인식 개발 환경
-
Kaldi Speech Recognition Toolkit : 음성인식 및 신호 처리를 위해 C++로 작성된 가장 대표적인 오픈소스 ASR(automatic speech recognition) Toolkit 이다. Unix/Linux 계열 플랫폼 기반으로 개발되어 있다. (Windows 계열에 설치하는 방법이 있긴 하지만 추천하지 않는다. docker 컨테이너를 이용할 수도 있다.)
-
Zeroth : Kaldi 기반 한국어 ASR 오픈소스 프로젝트. Kaldi 음향모델에 한국어 언어모델을 추가하였다. MoreCoin App을 통해 음성 데이터 및 음성에 대한 텍스트 데이터를 Crowd sourcing 하여 공유하는 플랫폼을 이용할 수 있다.
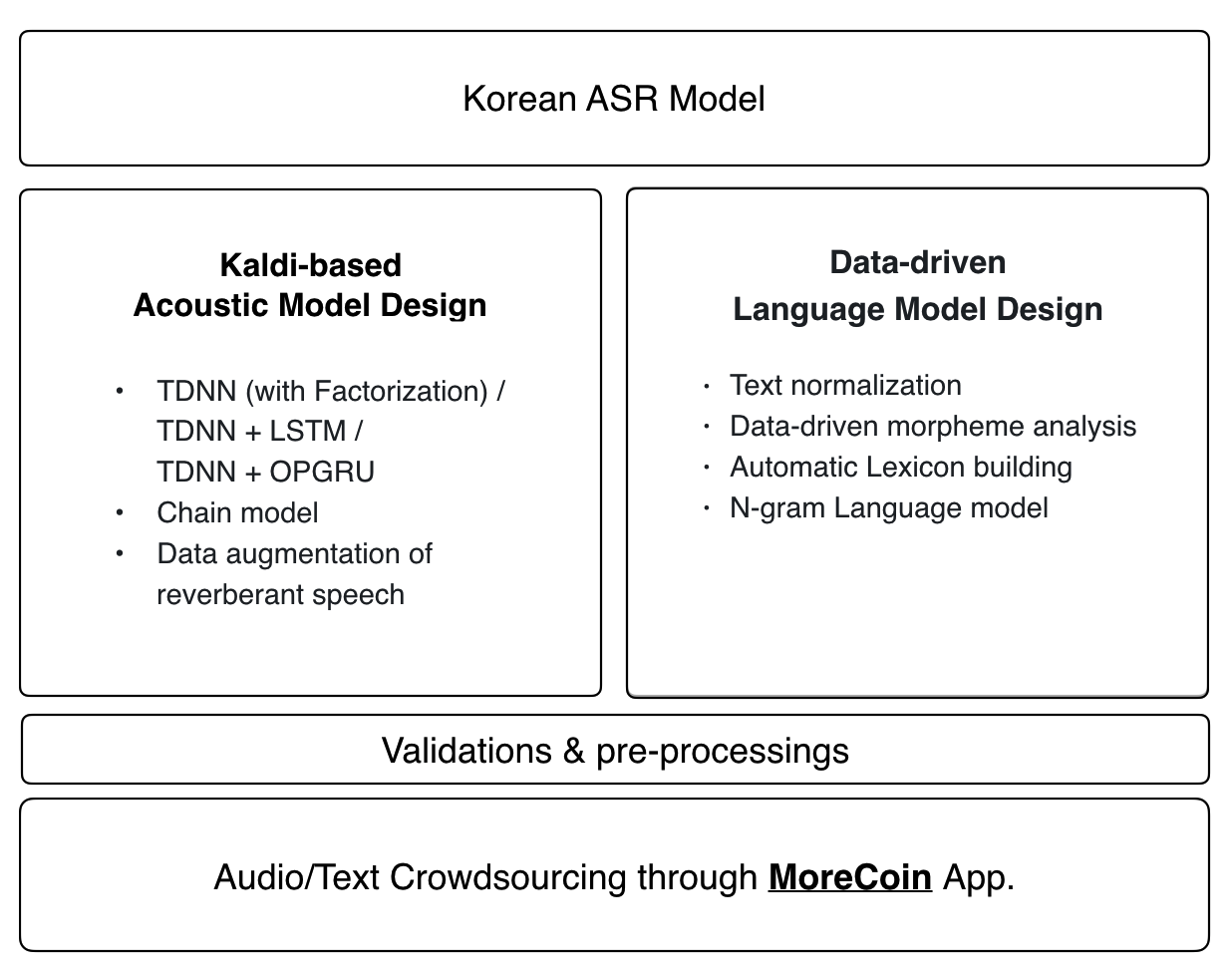
-
ETRI 음성인식 API : 한국어, 영어, 다국어(일본어/중국어/독어/불어/스페인어/러시아어/베트남어)에 대한 음성인식 서비스로서, 사용자가 발성한 녹음된 입력 음성 데이터(단위 파일 또는 버퍼)를 음성인식 서버로 전달하면 문자(텍스트)로 변환된 결과를 제공해준다. ETRI 음성인식 기술은 기술이전을 받아 독자적인 솔루션을 개발할 수도 있다.
-
Google Cloud Machine Learning API : STT(Speech to Text) API and TTS(Text to Speech) API를 이용할 수 있다. 상대적으로 쉽게 음성인식 서비스를 개발할 수 있지만, 영어에 비해 한국어에 대한 성능은 만족스럽지 않다.
Google STT(Speech to Text) API 실습
-
실습을 위해서는 Google Cloud Machine Learning API 사용을 위해, Google 계정에 Billing Account 설정 및 Private Key 발급이 필요 합니다. 아래 문서를 참고해서 환경설정 해주시기 바랍니다.
- google cloud speech-to-text 개발환경 설정하기 : Google Drive 링크(PDF)
-
github aiqa repository를 clone 합니다. 기존에 clone 되어 있는 경우는 pull 명령을 사용하여 checkout 합니다.
git clone https://github.com/sungalex/aiqa.git 또는 git pull origin master -
아래 명령으로 필요한 패키지를 추가로 설치 합니다.
pip install google-cloud-speech pip install pyaudio- anaconda를 사용하는 경우,
pip install명령어를 사용하여 설치 합니다.
- anaconda를 사용하는 경우,
-
STT 폴더의 파일을 jupyter notebook에서 학습 합니다.
jupyter notebook