[Study4] Computer Vision and CNN(Convolutional Neural Network)
Computer Vision 개요
컴퓨터 비전(Computer Vision)은 인공지능(Artificial Intelligence)의 한 분야로서, 시각에 해당하는 부분을 연구하는 컴퓨터 과학의 연구 분야 중 하나이다.
OpenCV
OpenCV는 크로스플랫폼과 실시간 이미지 프로세싱에 중점을 둔 오픈 소스 컴퓨터 비전 라이브러리이다. Windows, Linux, OS X(macOS), iOS, Android 등 다양한 플랫폼을 지원한다.
C++로 작성되어 있으며, 다양한 언어로 랩핑된 라이브러리가 존재(Python도 지원) 하며, 영상 관련 라이브러리의 사실상 표준의 지위를 가지고 있다. 조금이라도 영상처리가 들어간다면 필수적으로 사용하게 되는 라이브러리 이다.
OpenCV를 Study 하는데 참고할 사이트는;
CNN(Convolutional Neural Network) 개요
컨벌루션 뉴럴 네트워크(CNN 또는 ConvNet)는 이미지에서 객체, 얼굴, 장면을 인식하기 위해 패턴을 찾는 데 유용하다.
자율 주행 자동차, 얼굴 인식 애플리케이션과 같이 객체 인식과 컴퓨터 비전이 필요한 분야에서 CNN을 많이 사용한다.
CNN의 네트워크 일반적인 구성은 아래와 같다.
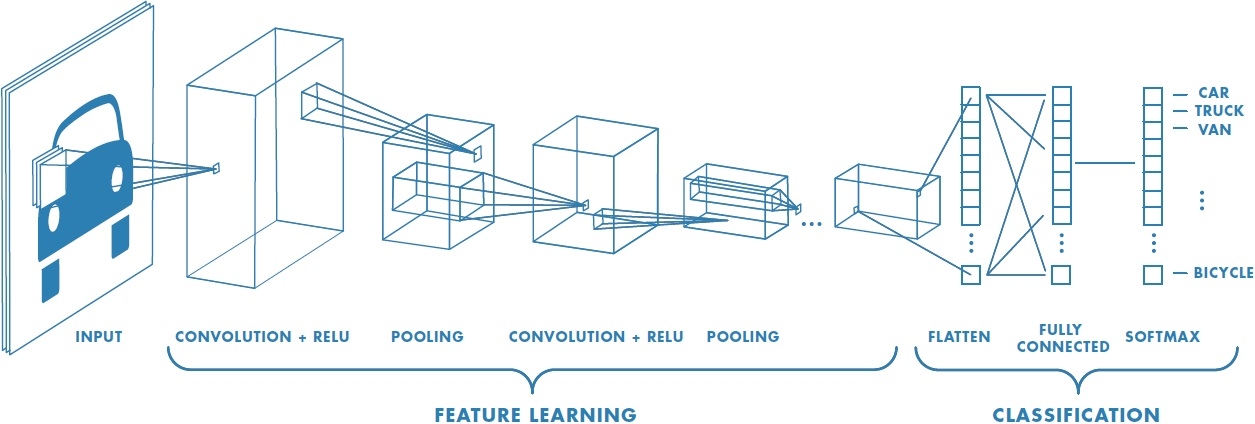
CNN에서는 각 계층 사이에 3차원 데이터와 같이 입체적인 데이터가 흐른다는 점에서 완전연결 신경망과 다르다.
- 완전연결 계층은 데이터의 형상이 무시됨
- 이미지 데이터의 경우 세로, 가로, 채널(색상)로 구성된 3차원 데이터 이지만, 완전연결 계층에 입력할 때는 3차원 데이터를 평평한 1차원 데이터로 바꿔줘야 함
- 이미지는 3차원 형상이고, 이 형상에는 소중한 공간적 정보가 담겨 있으며, 공간적으로 가까운 픽셀은 값이 비슷하거나, RGB의 각 채널은 서로 밀접하게 관련되어 있거나, 거리가 먼 픽셀끼리는 별 연관이 없는 등, 3차원 속에서 의미를 갖는 본질적인 패턴이 숨어 있음
- 완전 연결 계층은 형상을 무시하고 모든 입력 데이터를 동등한 뉴런(같은 차원의 뉴런)으로 취급하여 형상에 담긴 정보를 살릴 수 없음
- 합성곱 계층은 형상을 유지함. 이미지를 3차원 데이터로 입력 받으며, 다음 계층에도 3차원 데이터로 전달함
- CNN에서는 합성곱 계층의 입출력 데이터를 특징 맵(Feature Map) 이라고도 함. 입력 데이터를 입력 특징 맵, 출력 데이터를 출력 특징 맵 이라고 함
CNN을 Study 하는데 참고할 사이트는;
- 컨벌루션 뉴럴 네트워크란 : CNN 개념 설명 부분 참고하기
- 스탠포드 CS231n: Convolutional Neural Networks for Visual Recognition - 강의노트(한글) : 컨볼루션 레이어 데모 부분 참고하기
- 합성곱 신경망(CNN, Convolutional Neural Network) : CNN 요약 정리
CNN 따라하기
deep-learning-from-scratch Github Repository를 Clone 해서 Jupyter Notebook에서 _mystudy 폴더의 07_CNN.ipynb 파일 내용을 따라해본다.
- deep-learning-from-scratch - CNN 코드 보기 : 밑바닥부터 시작하는 딥러닝 도서에 포함된 CNN에 대한 설명이 요약되어 있다.
위의 코드는 함수를 직접 구현해보면 CNN을 이해하는데는 도움이 되지만, 실제는 아래와 같이 Tensorflow를 사용하면 훨씬 쉽게 더 좋은 결과를 만들 수 있다. (최적화된 알고리즘을 사용하여 훨씬 성능이 좋다)
- Tensorflow 튜토리얼 - 합성곱 신경망 : MNIST 데이터셋에 대해 tf.keras.Sequential 모델을 사용했을 때 보다 더 좋은 결과를 보여준다. (tf.keras.Sequential 모델을 사용하는 Tensorflow MNIST 튜토리얼과 비교해본다)