AutoEncoder
1. AutoEncoder 란?
-
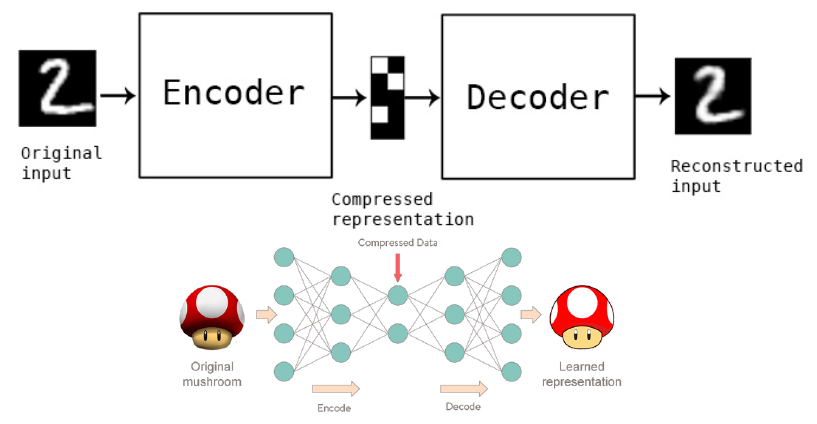
자기 자신을 학습하는 Unsupervised Learning
- 입력과 출력층의 뉴런 수가 동일
- encoder 부분만 분리하면 Clustering model이 됨
- decoder 부분만 만들면 Generation model이 됨
- AutoEncoding 과정에 de-noising 처리됨(인코딩 과정에서 입력된 데이터의 핵심 Feature 정보만 Hidden Layer에서 학습하고, 나머지 정보는 손실시킴. 디코딩 과정에서 Hidden Layer의 출력값을 뽑았을 때 완벽한 값 복사가 아닌 입력값의 근사치가 됨)
-
AutoEncoder 종류 : https://iq.opengenus.org/types-of-autoencoder
2. Encoder/Decoder란?
- Encoder란?
- 일반적 의미 : 물리 환경으로부터 피드백을 제공하는 센서 장치
- 데이터 과학에서의 의미 : 분석을 위해 데이터를 부호화 함
- set() Operation을 통해 속성을 추출하고, 순번을 매핑한 결과가 Encoder임
- Decoder란?
- Encoding된 데이터를 원래의 형태로 복원함
- Encoder의 Key:Value를 뒤집은 결과가 Decoder임(Key가 Value가 되고, Value가 Key가 됨)
- Encoder는 set() 함수로 Key를 추출한 후 dict() 객체를 직접 만들어서 구현할 수도 있고, Scikit-Learn의 preprocessing.LabelEncoder()를 사용하여 fit()으로 생성할 수도 있음
2.1 Encoder/Decoder 직접 만들기
# Encoder 만들기
data = ["ACCOUNTING","RESEARCH", "SALES", "RESEARCH", "RESEARCH"]
enc = { k:v for v,k in enumerate( set(data))}
print(enc['SALES']) # 0
# Decoder 만들기
dec = { v:k for v,k in enumerate(set(data)) }
print(dec[0]) # 'SALES'
2.2 Encoder/Decoder 사용하기
enc_data = [ enc[i] for i in data]
print(enc_data) # [2, 1, 0, 1, 1]
dec_data = [ dec[i] for i in enc_data ]
print(dec_data) # ['ACCOUNTING', 'RESEARCH', 'SALES', 'RESEARCH', 'RESEARCH']
2.3 Scikit-Learn 기반 Encoding/Decoding
# Encoder/Decoder 생성
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
data = ["ACCOUNTING","RESEARCH", "SALES", "RESEARCH", "RESEARCH"]
le.fit(data) # Encoder/Decoder가 학습됨
# Record 확인
le.classes_ # array(['ACCOUNTING', 'RESEARCH', 'SALES'], dtype='<U10')
# Encoding
le.transform(data) # array([0, 1, 2, 1, 1])
# Decoding
le.inverse_transform([0, 0, 1, 2]) # array(['ACCOUNTING', 'ACCOUNTING', 'RESEARCH', 'SALES'], dtype='<U10')
3. Keras AutoEncoder on Iris Dataset
- reference : https://www.kaggle.com/shivam1600/autoencoder-on-iris-dataset
- Source : https://github.com/sungalex/aiqa/blob/master/keras_AutoEncoder.ipynb
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# Importing Data
data = pd.read_csv("iris.csv")
display(data.head())
x_train, x_test, y_train, y_test = train_test_split(data[['Sepal.Length', 'Sepal.Width',
'Petal.Length', 'Petal.Width']],
data['Species'],test_size=0.1, random_state=1)
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
from tensorflow.keras.callbacks import TensorBoard
from tensorflow.keras.optimizers import RMSprop
# this is the size of our encoded representations
encoding_dim1 = 6
encoding_dim2 = 4
encoding_dim3 = 2
input_dim = 4
# this is our input placeholder
input_img = Input(shape=(input_dim,))
# "encoded" is the encoded representation of the input
encoded = Dense(encoding_dim1)(input_img)
encoded = Dense(encoding_dim2)(encoded)
encoded = Dense(encoding_dim3)(encoded)
# "decoded" is the lossy reconstruction of the input
decoded = Dense(encoding_dim2)(encoded)
decoded = Dense(encoding_dim1)(decoded)
decoded = Dense(input_dim)(decoded)
# AutoEncoder 모델 생성(this model maps an input to its reconstruction)
autoencoder = Model(input_img, decoded)
# Encoder 모델 생성(this model maps an input to its encoded representation)
encoder = Model(input_img, encoded)
# Decoder 모델 생성
# create a placeholder for an encoded (2-dimensional) input
encoded_input = Input(shape=(encoding_dim3,))
# retrieve the last layer of the autoencoder model
decoder_layer = autoencoder.layers[-3](encoded_input)
decoder_layer = autoencoder.layers[-2](decoder_layer)
decoder_layer = autoencoder.layers[-1](decoder_layer)
# create the decoder model
decoder = Model(encoded_input, decoder_layer)
# compile
opt=RMSprop(lr=0.001)
autoencoder.compile(loss='mean_squared_error', optimizer=opt)
autoencoder.summary()
# training
autoencoder.fit(x_train, x_train,
epochs=333,
batch_size=123,
shuffle=True,
validation_data=(x_test, x_test),
callbacks=[])
# encode and decode some data points
# note that we take them from the *test* set
encoded_datapoints = encoder.predict(x_test)
decoded_datapoints = decoder.predict(encoded_datapoints)
# print('Original Datapoints :')
# print(x_test)
# print('Reconstructed Datapoints :')
# print(decoded_datapoints)
# Plotting Encoded Features
encoded_dataset = encoder.predict(x_test[['Sepal.Length', 'Sepal.Width',
'Petal.Length', 'Petal.Width']])
# Encode Dataset
plt.scatter(encoded_dataset[:,0], encoded_dataset[:,1], c=y_test.astype('category').cat.codes)
plt.show()
# Decoded Dataset(reconstruncted)
decoded_dataset=decoder.predict(encoded_dataset)
plt.scatter(decoded_dataset[:,2], decoded_dataset[:,3], c=y_test.astype('category').cat.codes)
plt.show()
# Orignal Data
plt.scatter(x_test['Petal.Length'], x_test['Petal.Width'],c=y_test.astype('category').cat.codes)
plt.show()
4. AutoEncoder 응용사례
4.1 Anomaly Detection
- 정상 데이터에 비해 비정상 데이터 수가 너무 적으면(1만배 이상 차이가 나면) 지도학습으로 학습이 잘 안됨
- AutoEncoder 모델로 정상을 학습 -> 구현시 재구성 Error가 크면 비정상 이라고 간주함
4.2 Denoising Autoencoder
- 오토인코더가 의미있는 특성(feature)을 학습하도록 제약을 주기 위해 입력에 노이즈(noise, 잡음)를 추가
- 노이즈가 없는 원본 입력을 재구성하도록 학습시키는 것
- 노이즈 발생 방법
- 입력에 가우시안(Gaussian) 노이즈를 추가
- 드롭아웃(dropout)처럼 랜덤하게 입력 유닛(노드)를 끔