[Study6] NLP(Natural Language Processing) - RNN/LSTM에서 BERT까지
[AI와 QA의 만남] - Study Day6 (학습일: ‘20.06.10, update: ‘20.06.10)
딥러닝을 이용한 자연어처리
NLP Deep Learning Model의 역사

RNN & LSTM
-
RNN은 자연어(Natural Language)나 음성신호, 주식과 같은 연속적인(sequential) 시계열(time series) 데이터에 적합한 모델 입니다.
-
RNN은 은닉층의 노드에서 활성화 함수를 통해 나온 결과값을 출력층 방향으로도 보내면서, 다시 은닉층 노드의 다음 계산의 입력으로 보내는 특징을 갖고있습니다.
-
kt ds 교육센터 RNN & LSTM 강의자료 (D Plus/파인코드 이숙번 강사) : https://github.com/sungalex/aiqa/ Repository를 clone 하여 “RNN_LSTM.pdf” 파일 참조
-
RNN(Recurrent Neural Network) 기본 모델
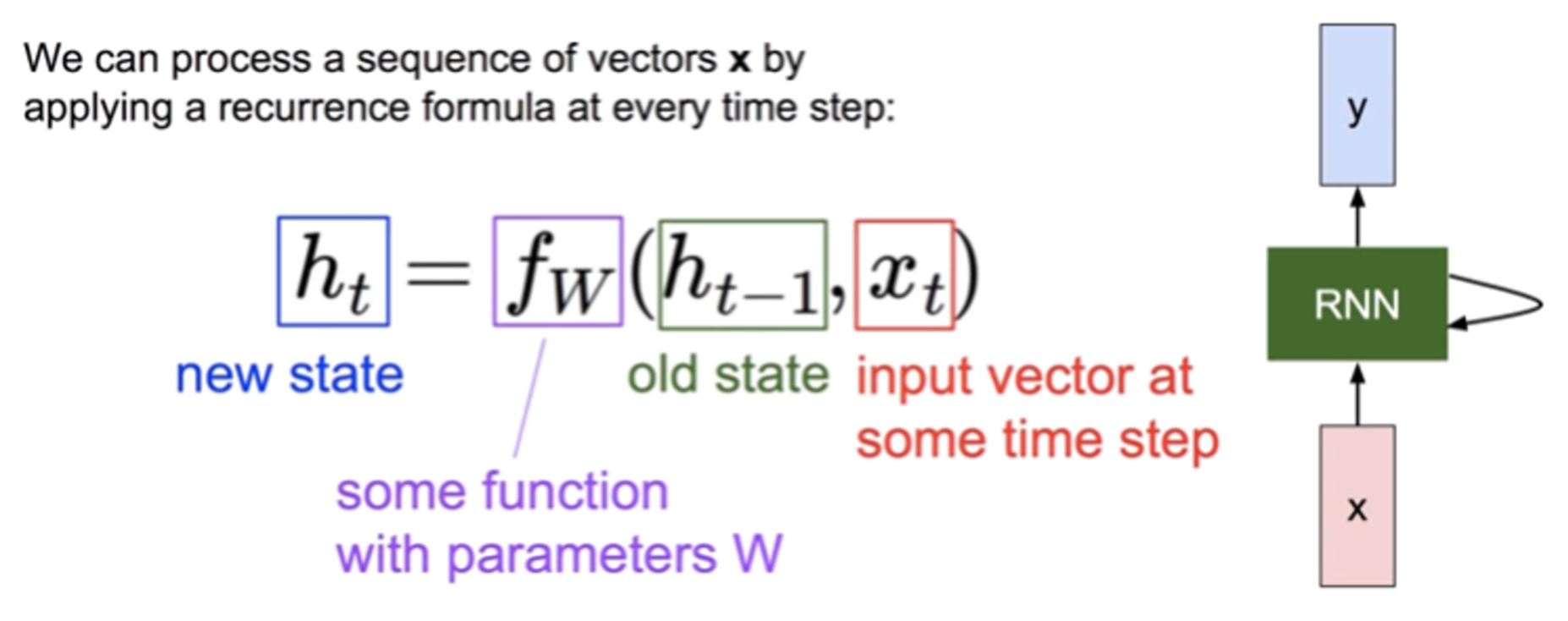
-
RNN Examples
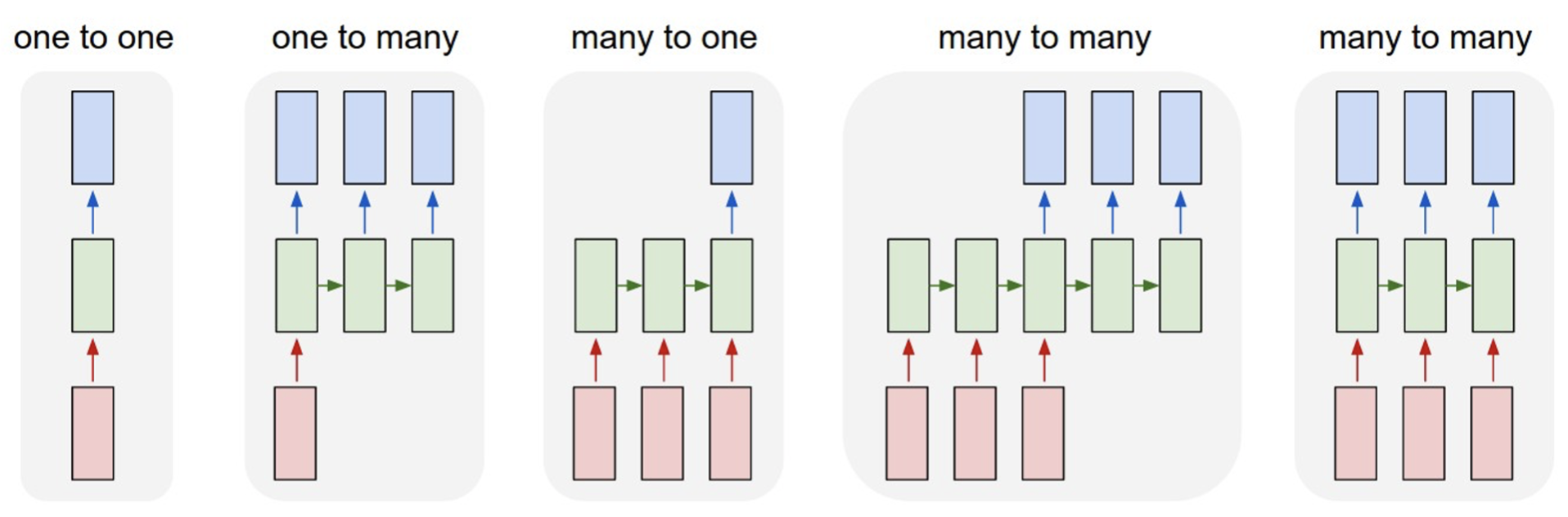
- one to one : 이미지 입력 -> 이미지 분류 (개/고양이 사진 분류)
- one to many : 이미지 입력 -> 이미지 Captioning (문장 생성)
- many to one : 문장 입력 -> 감정분석 결과 (긍정/부정)
- many to many : 문장 입력 -> 문장 출력 (기계번역)
- many to many : 비디오 입력 -> (동기화된) 결과 출력 (비디오 프레임별 분류)
-
LSTM (Long Short Term Memory)
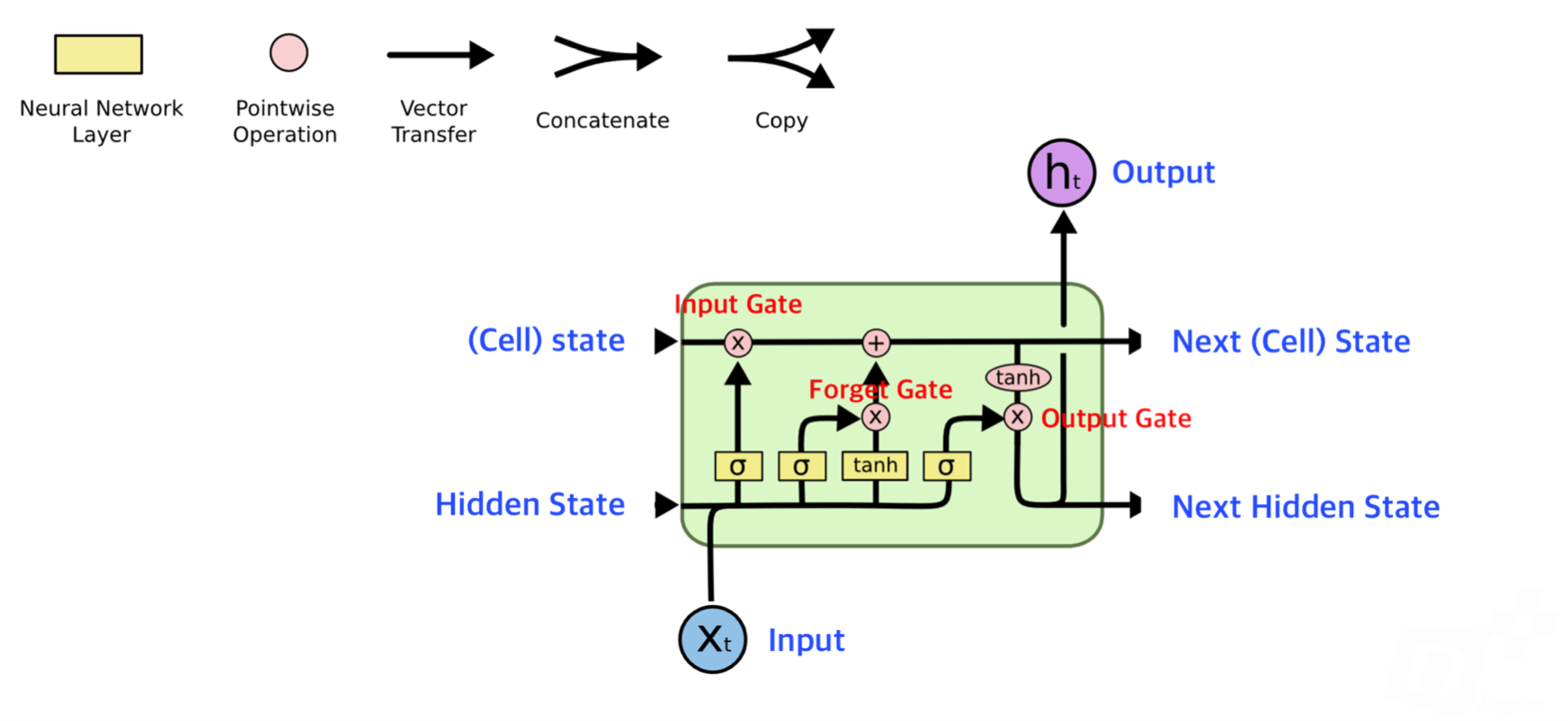
- RNN은 tanh 함수가 중첩되면 0에 수렴하는 문제 때문에 RNN 노드를 많이 중첩 시킬 수 없습니다(Deep Network을 구성할 수 없습니다). LSTM은 이러한 RNN의 문제점을 해결하기 위해, Long Term Memory와 Short Term Memory를 함께 가지도록 만든 모델 입니다.
-
RNN & LSTM 학습 참고 사이트
-
RNN/LSTM keras 샘플 코드 : sungalex’s Github Repository를 clone 하여 “RNN_LSTM_example.ipynb” 파일을 Jupyter Notebook에서 학습하기
- Jupyter Notebook Viewer 사이트에서 위의 코드를 바로 확인할 수도 있음
BERT & KoBERT
-
BERT(Bidirectional Encoder Representations form Transformer)는 구글에서 개발한 자연어처리 신경망 구조이며, Transformer 구조의 Encoder를 적층시켜 만들었습니다.
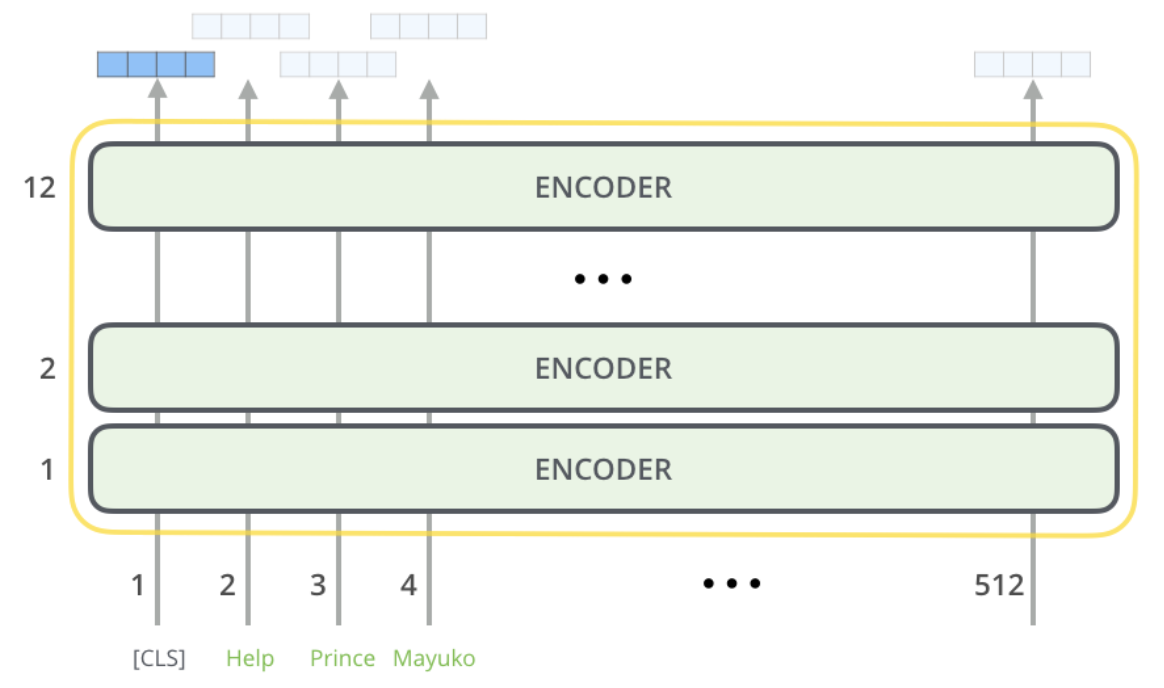
-
BERT Structure : Pre-Training and Fine-Tuning
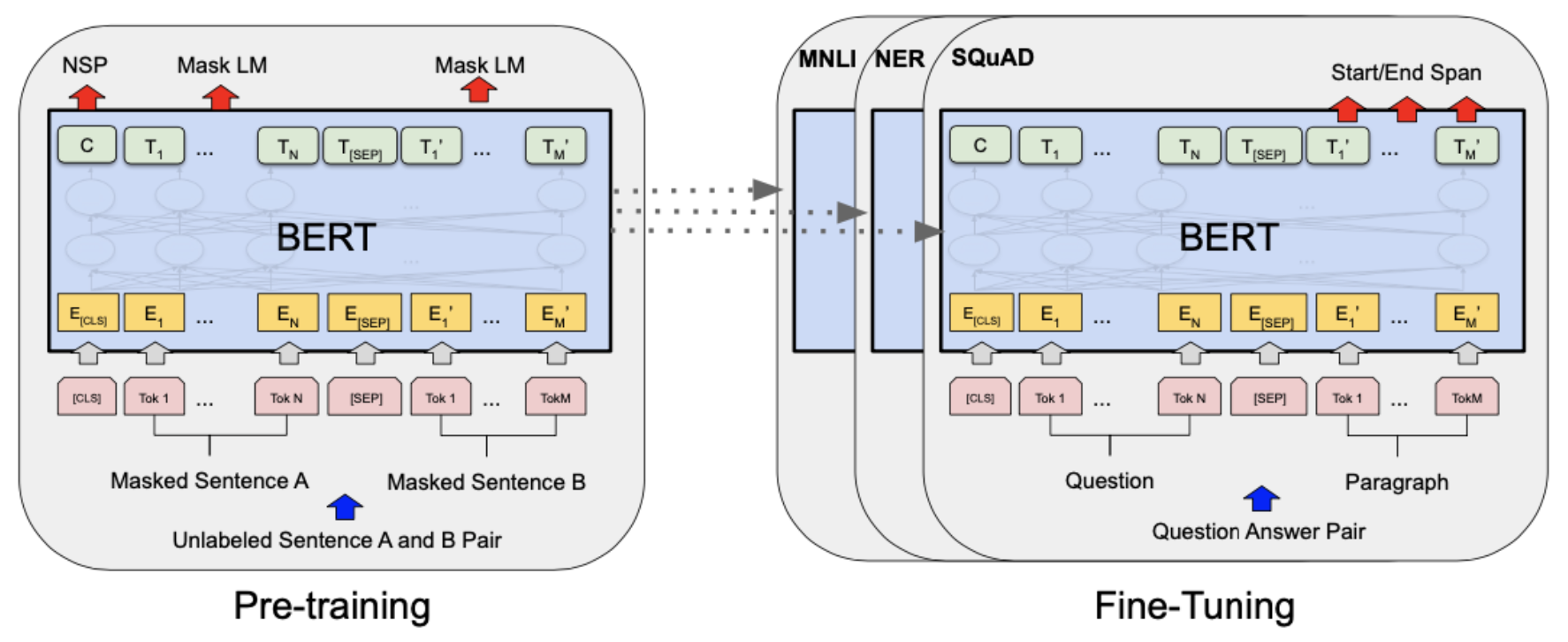
-
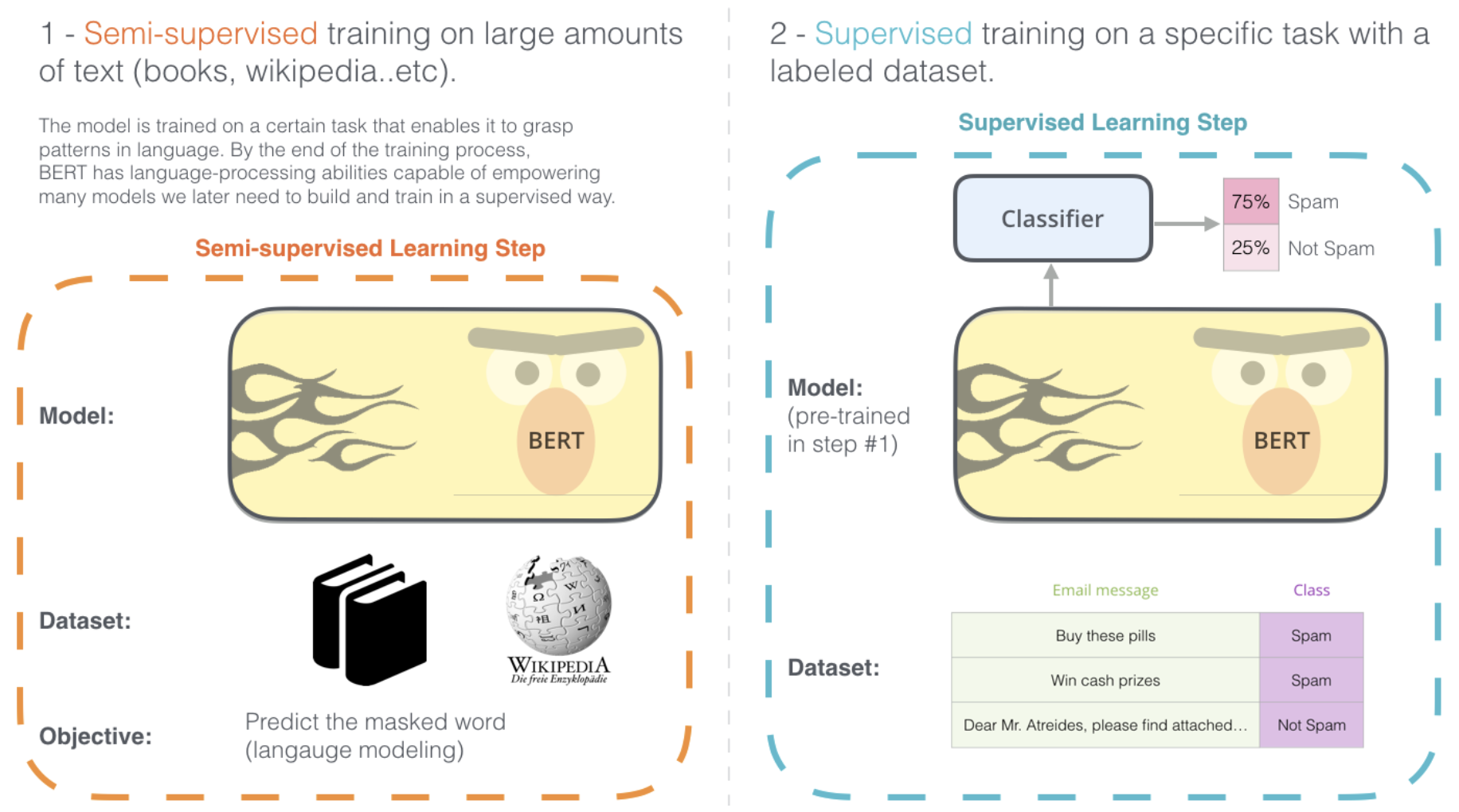
BERT는 기본적으로 wiki나 book data와 같은 대용랑 unlabeled data로 모델을 미리 학습 시킨 후, 특정 task를 가지고 있는 labeled data로 transfer learning을 하는 모델입니다.
-
BERT의 2단계 Step : (Step1) pre-trained(trained on un-annotated data) model을 다운로드 한다 -> (Step2) 해결하고자 하는 문제에 집중하여 fine-tuning을 한다 (위 그림에서는 스팸 분류를 위한 Classifier 부분만 추가적으로 학습한다)
-
BERT는 모델의 크기에 따라 Base 모델과 Large 모델의 Pre-Trained 모델을 제공합니다.
-
-
BERT Github 사이트 : TensorFlow code and pre-trained models for BERT
-
BERT 학습 참고 사이트
-
Colab에서 TPU로 BERT 처음부터 학습시키기 - Beomi’s Tech Blog
-
The Illustrated BERT : Jay Alammar’s Blog
-
A Visual Guide to Using BERT for the First Time : Jay Alammar’s Blog -> Github notebook 보기 또는 Colab에서 실행하기
-
Cloud 서비스로 BERT 경험하기 : AIN Cloud beta 서비스 -> “AIN Cloud beta로 Open Resource 경험하기” 블로그 참고
-
-
KoBERT는 한글 위키와 뉴스 텍스트를 기반으로 Pre-Training을 한 한글 자연어처리를 위한 BERT 모델 입니다. SKT-Brain에서 개발하여 공개하였습니다.
블로그 작성 참고자료
[참조1] Fastcampus On-line 강의(“올인원패키지: 머신러닝과 데이터분석 A-Z”) - 김용담 강사 강의자료
[참조2] BERT 논문정리 - mino-park7’s Blog
[참조3] BERT란 무엇인가? - Brunch/Tristan’s Blog